
最近、コンピュータービジョン技術の進化が目まぐるしくその中でも最新のGANに関する技術が凄いので改めてGANについて知っておこうと思います。
GAN(generative adversarial networks)は、2014年にIan Goodfellowらによって初めて紹介された、最近の機械学習フレームワークのクラスです。
下記の本の著者としても有名です。
" type="text/html" width="500" height="550" frameborder="0" allowfullscreen style="max-width:100%" src="https://read.amazon.com.au/kp/card?preview=inline&linkCode=kpd&ref_=k4w_oembed_vuocyTA6K5fXiQ&asin=0262035618&tag=kpembed-20"></iframe>)
GANと似たようなものにVAEがありますが、違いとしてGANはCNNなどの深層学習手法を用いて生成モデリングを行う強力なアプローチを使っています。
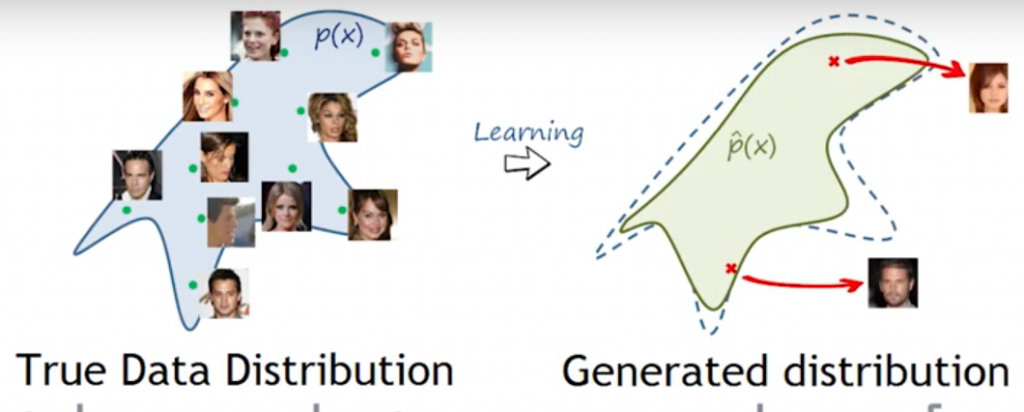
生成モデリングとは、機械学習における教師なしの学習タスクで、入力データの規則性やパターンを自動的に発見・学習し、そのモデルを使って、元のデータセットから尤もらしく引き出されたであろう新しい例を生成・出力することを意味します。
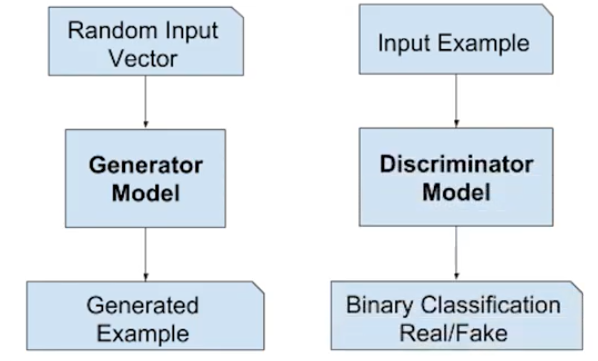
GANはこの生成モデルを学習する画期的な方法で、問題を2つのサブモデルを持つ教師付き学習問題として組み立てます。
新しい画像を生成するために学習する生成器モデルと、画像を本物か生成された偽物かに分類しようとする識別器モデルです。
この2つのモデルは、ゼロサムゲーム(敵対的なゲーム)で一緒に学習され、識別器モデルが騙され、生成器モデルが判別ができない画像を生成するようになるまで学習されます。
この場合のゼロサムとは、識別器が本物のサンプルと偽物のサンプルの識別に成功した場合、識別器に報酬が与えられるか、モデルのパラメータを変更する必要がないのに対し、生成器はモデルのパラメータを大幅に更新するペナルティが課せられることを意味します。
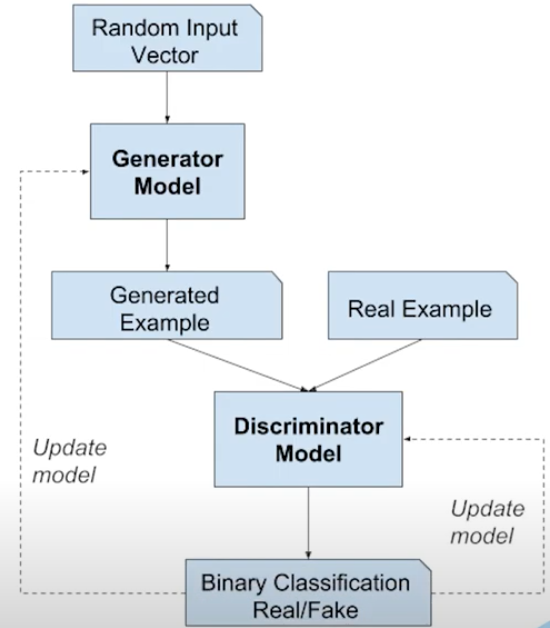
逆に,生成器が識別器を騙した場合は報酬が与えられるか、モデルとパラメータの変更が不要となるが、識別器はペナルティを受け、モデルとパラメータが更新される。
具体的例として、生成器は偽物のお金を作ろうとする偽造者のようなもので、識別器は正規のお金を認めて偽物のお金を捕まえようとする警察のようなものだと考えることができます。
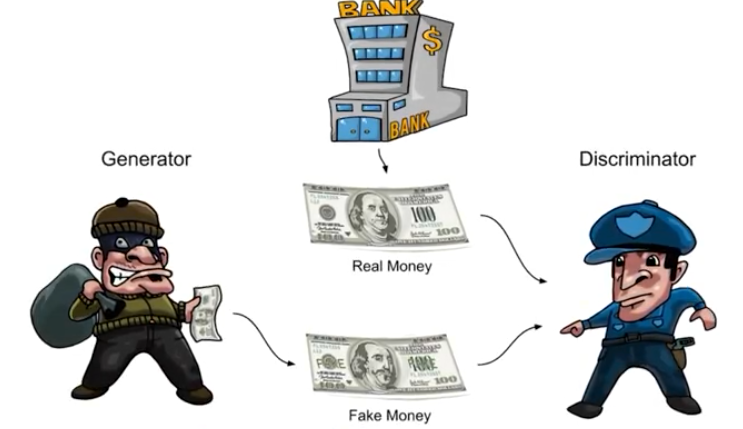
このゲームで成功するためには、偽造者は本物のお金と見分けがつかないようなお金を作ることを学習しなければならず、生成器ネットワークは学習データと同じ分布から抽出されたサンプルを作ることを学習しなければならない。
GANのフレームワークはゲーム理論のツールを使って分析することができるので、GANは一般的に「敵対的」と呼ばれています。
このGANはさまざまな方面で使われています。
一つは入力された画像の高解像度バージョンを生成し、新しい芸術的な画像、スケッチ、絵画などを作成する機能です。

更にGANは、昼から夜、夏から冬など顔画像以外の分野である写真を翻訳する能力を持っています。
GANは、今では人間には見分けがつかないほどリアルな写真を生成することができました(細部を見れば違和感はありますが・・・)。
現実には存在しない物や風景、人の写真であることが人間にはわからないほどリアルな写真を生成することができます。
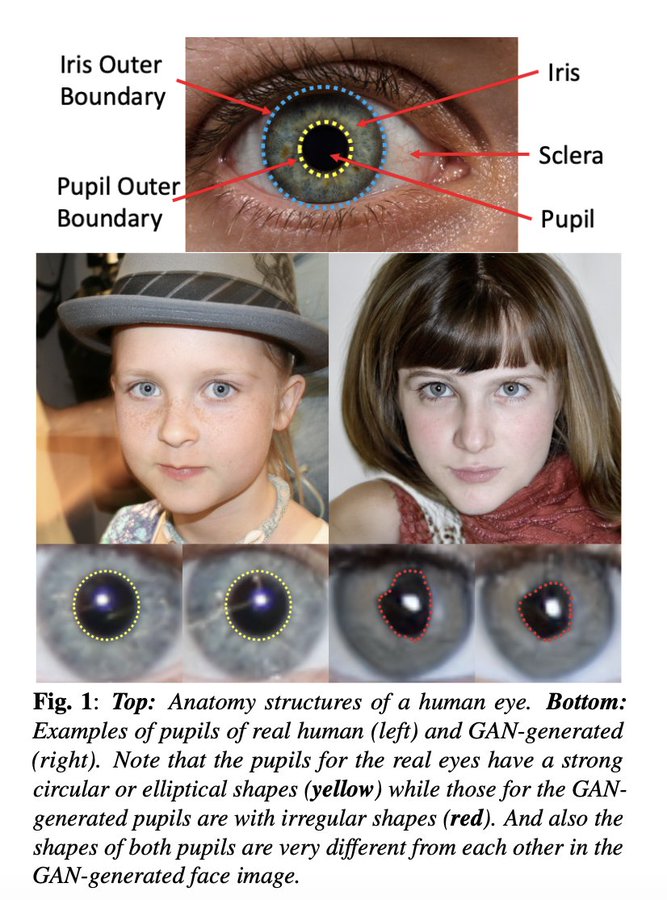
深層学習をビジネスに応用したくても、データセットが足りず断念することも多々あります。そこでGANを使ったdata augumentationを行う実験もあります。
GANは深層学習分野でもあつい分野なのでこれを機に学んでみてはいかがでしょう。














