画像生成AIが注目されている理由
結論として、ソースコードと学習済みのモデルも公開されたため。
今までにもお絵かきAIというのはDCGANなどでも開発されて使えるようにはなっていました。
ただし、悪用されたりすると危険なのでコードやモデルは公開せずAPIを通してのみ使用(無料・有料)できるといった制限を設けるのが主流でした。
Stable Diffusionはソースコードもモデルも公開してしまい、商用利用も可能だし、生成された画像は生成者のものという打ち出し方をしている。
これまでもOSSで公開されていたものもありましたが、生成される画像のクオリティがそこまでではありませんでした。ただし、Stable Diffusionは有料級のクオリティの画像が生成されます。
画像生成AIとは?
テキストや画像をインプットとして与えると、存在しない画像を自動で生成してくれる機械学習モデルのことをいいます。
Stable Diffusionの実装
学習済みのパラメータの容量は数GBと大きいため、GitHubなどにあげることはせずにHugging Faceが使用しているサーバーを利用します。
そこで、はじめにHugging Faceのアカウントを作成して準備を進めます。
Hugging Faceアカウント作成
以下のサイトに飛び、右上にある「Sign Up」をクリックします。
メールアドレスとパスワードを設定して、Nextボタンを押して進めます。
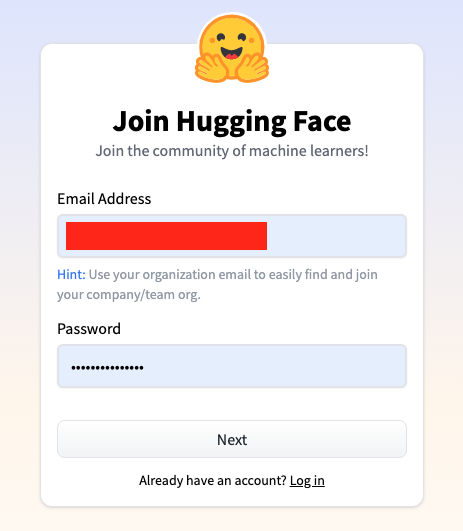
UserNameとFull nameと同意チェックが必須となってます。
Usernameは既存の名前と被っているとエラーになるので発生した場合には適宜変えてください。
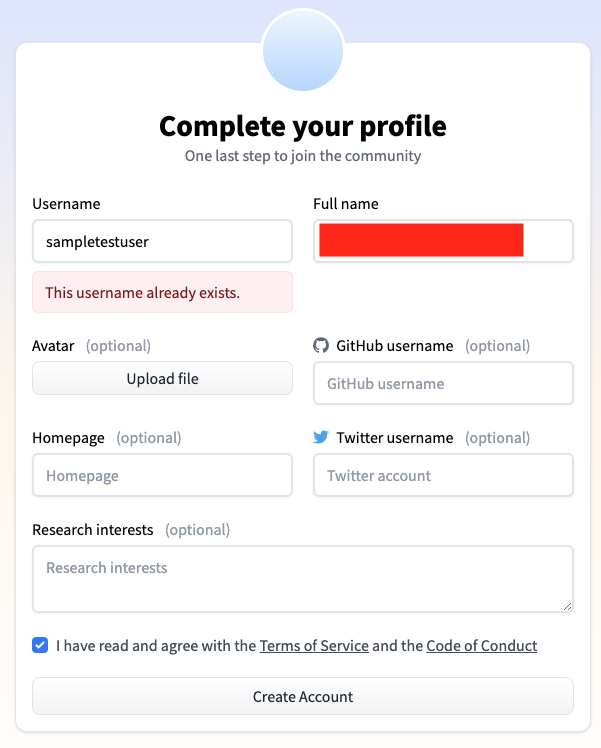
登録したメールアドレスに確認メールが飛ぶので、そちらからアカウントの有効化をします。
続いて、Hugging Faceの画面に戻り、左上の検索窓に「stable-diffusion-v1-4」と入力して飛ぶか、以下のリンクから飛んでください。
https://huggingface.co/CompVis/stable-diffusion-v1-4
このモデルを使用するために下の方にスクロールしてモデル使用のライセンス許諾にチェックします。

アクセストークンの取得
アクセストークンの取得については以下の手順で行います。
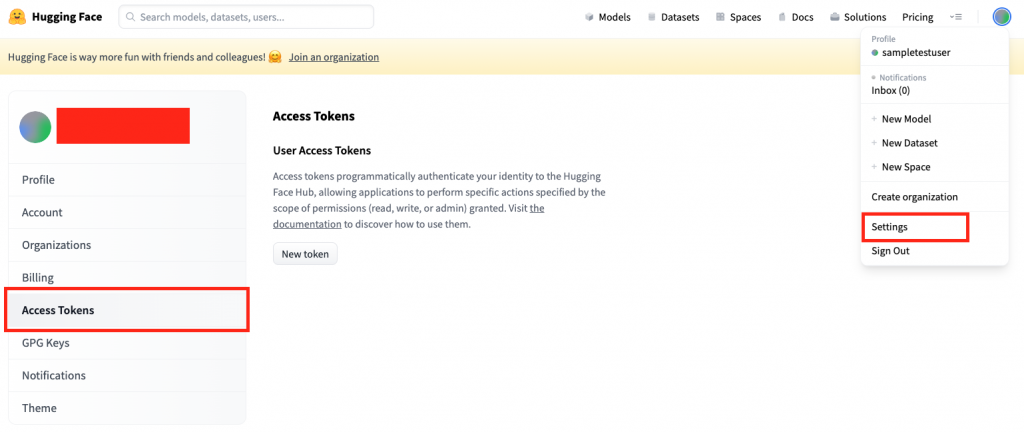
- 右上のアイコンからsettingsをクリック
- 左のメニューからAccess Tokensを選択
- 中央のNew tokenをクリック
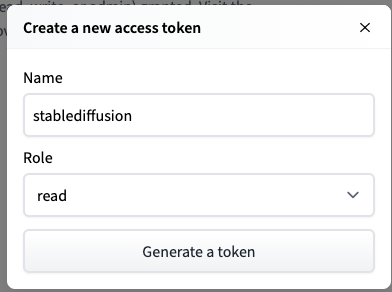
- モーダルが立ち上がるので、任意のNAMEを入力して、RoleはREADのままにしときます
- 表示されたアクセストークンをコピーしておきます。
以上で下準備が完了しました。
続いて、colabの方に移ります。
Google Colab上での実装
今回はGPUを使用するため、はじめにランタイムを変更してGPUを有効化しておきます。
まずはGPUが使われているかの確認を行います、
もし使われていないのであれば、タブの「ランタイム>ランタイムのタイプを変更」からGPUを選択後、再度実行してください。
!nvidia-smi必要なライブラリ一式をインストール
ここで重要なのは、diffusersでこれはStable Diffusionをはじめとする「拡散モデル」による画像生成を数行のコードで行えるようにするフレームワークです。
!pip install diffusers==0.2.4 transformers scipy ftfy先程コピーしたアクセストークンを変数に格納しておきます。
Access_Token="******"パイプラインを構築します。
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", use_auth_token=Access_Token)
pipe.to("cuda")最後に生成したい画像のテキストを渡して完成です。
promptの文字列を変えることで、生成画像を変更することができます。
prompt = "Kawaii Anime Girl"
image = pipe(prompt)["sample"][0]
# 保存
sentence = prompt.replace(' ','_')
out_path = sentence+'.png'
image.save(out_path)
# 表示
from IPython.display import Image,display
display(Image(out_path))今回出力した画像は次の通りです。seedを固定していないため生成画像は毎回違います。

結構崩れてしまっているので、イラスト生成には派生モデルであるWaifu Diffusionなどを使用した方が良さそうです。














