画像生成のモデルとして一番有名なのはGANですが、その中でも高い精度を誇っているのがStyleGAN系のモデルです。
使用例として、データセットのかさ増しのためにも使います。
例えば、人物の画像を増やしたい際に完全に別物を生成してもいいですが、同じ画像で目の色だけを変えたものを生成したい場合もあるかと思います。
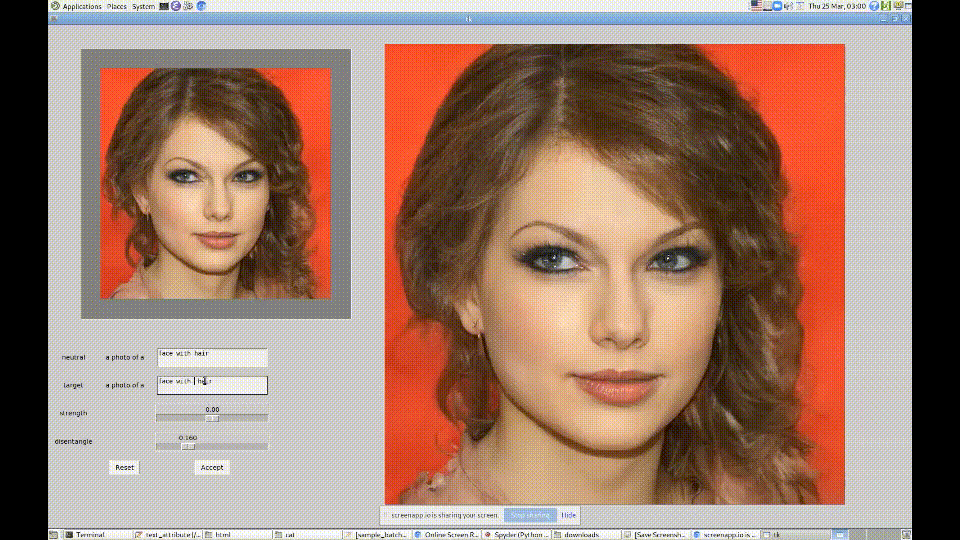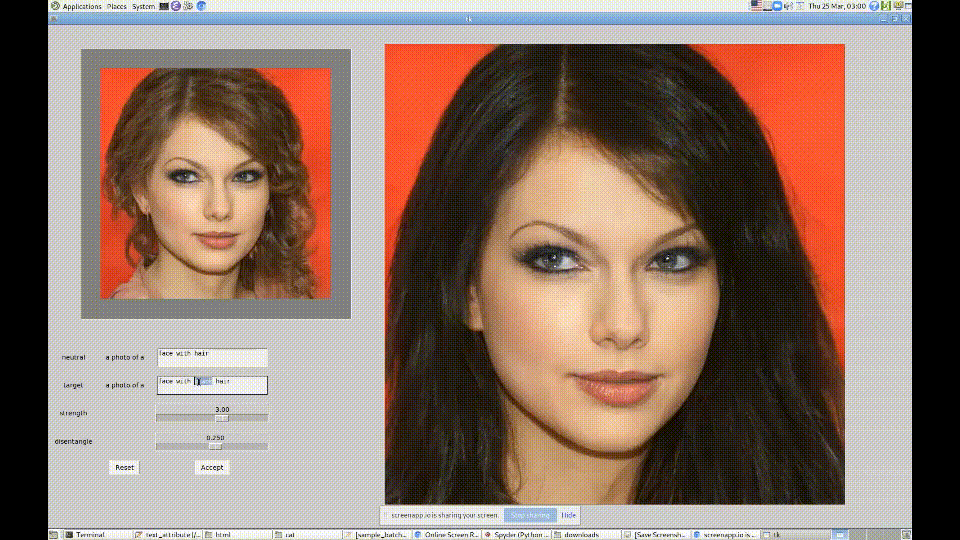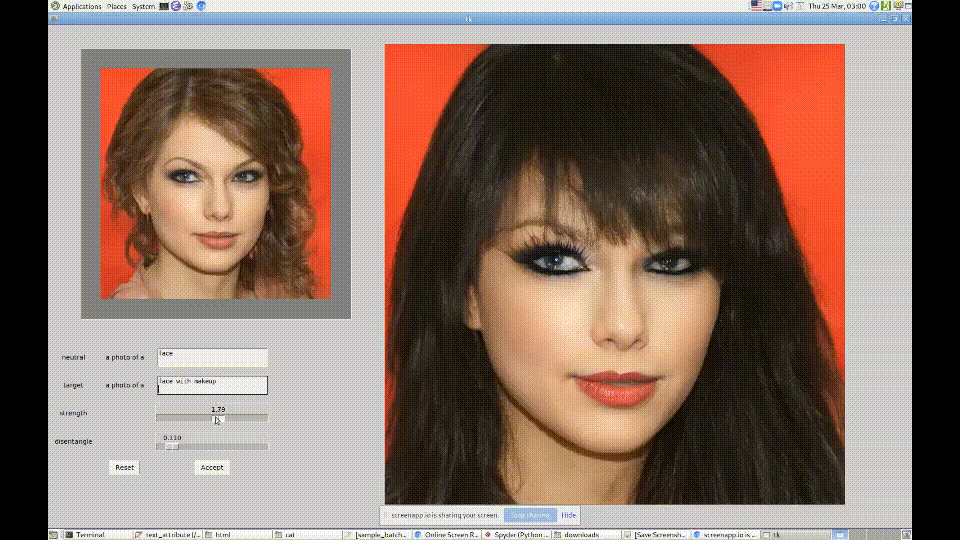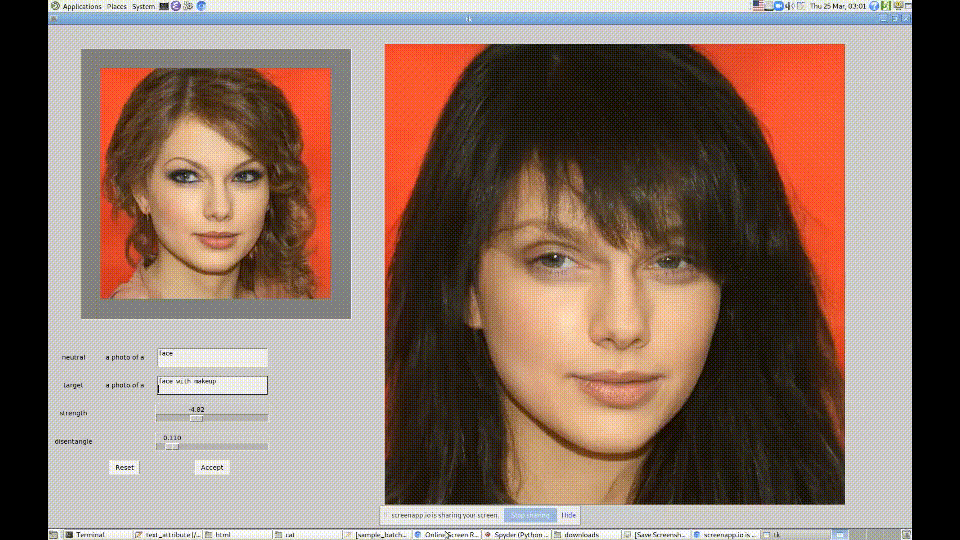
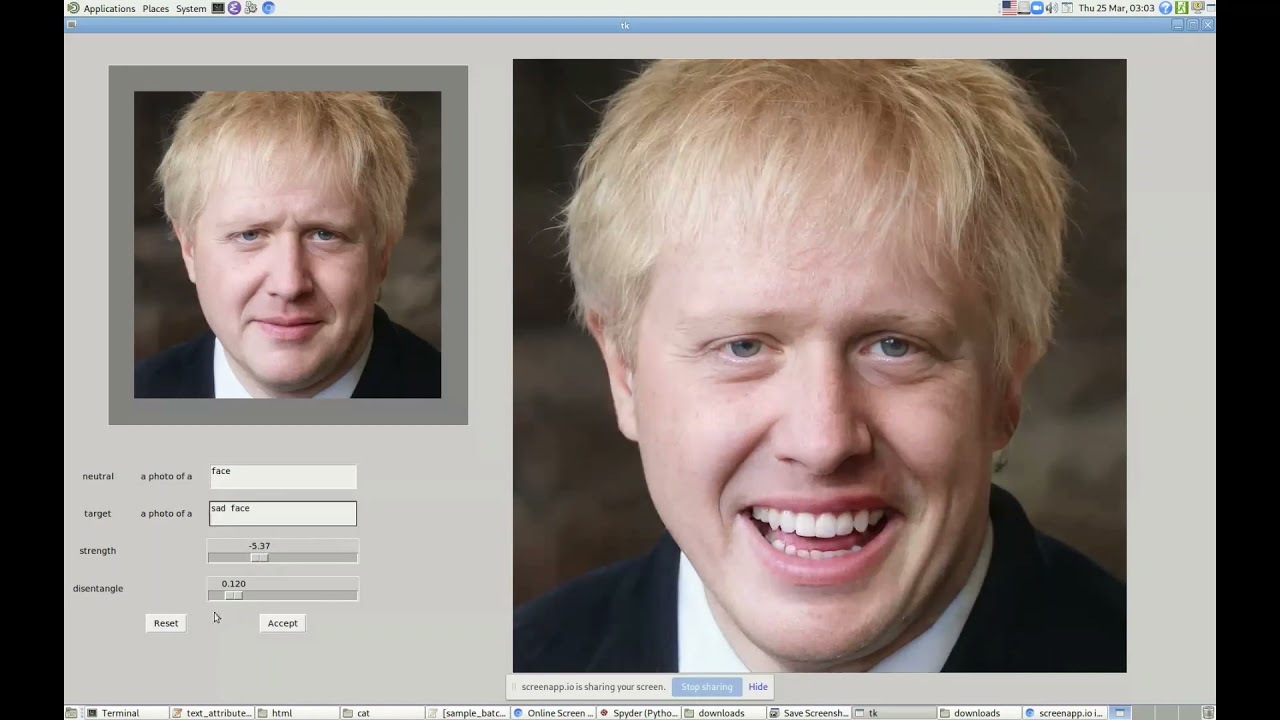
StlyeGANでも可能ですが、多くの作業が発生するため現実的ではありません。
そこで、StyleClipだとテキストだけで制御できるようになりました。
StyleGANとCLIPを使用してほぼ全ての顔の変形に対応することができます。
自身が欲しい結果を得るために、パラメーター調整もすぐに済むので時間は気にしなくて問題ありません。
https://github.com/orpatashnik/StyleCLIP
CLIPとは?
CLIPは一言でいうと、最近OpenAIが公開した画像とテキストの類似度を出力できるモデルです。
このモデルは画像とテキストの入力だけで、画像の修正をコントロールする役割を担っています。
どのように実現しているかというと、ウェブ上の多くの画像とテキストの組み合わせで学習されており、基本的に画像に表示される内容を理解することができます。
画像とテキストのペアで学習されているので、既存の画像にテキストの説明を効率的にマッチングさせることができます。
つまり、現在のモデルでもこの同じ原理を利用して、StyleGANが生成した画像を目的のテキスト変換に方向付けることができます。
公式の紹介
StyleClipの処理の流れ
はじめに入力画像を受け取ります。
画像では、wと呼ばれるエンコーダーを使って、潜在変数にエンコードされています。
この潜在変数は、CNNによって生成された画像を凝縮したものです。
そして、モデルの学習中に特定された画像に関する最も有用な情報が含まれています。
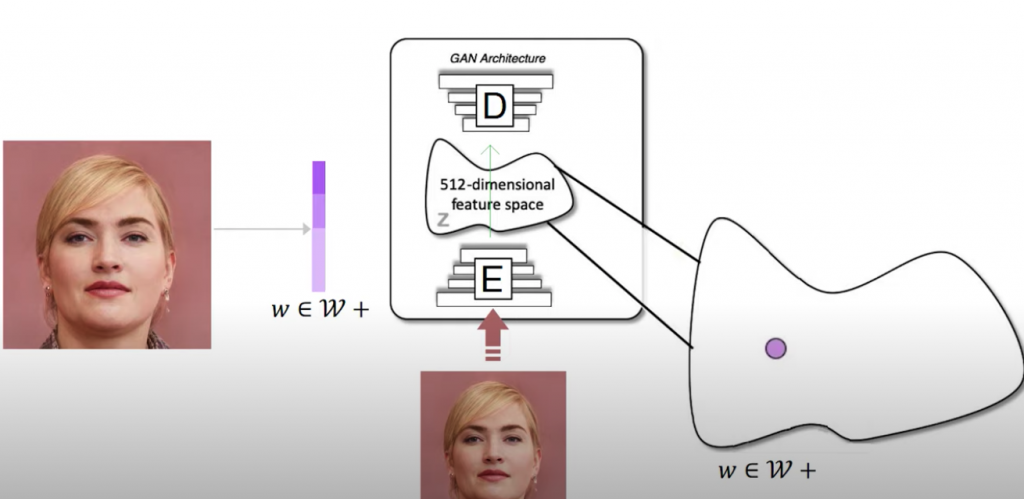
ここまではGANの処理とほぼ一緒です。
潜在変数=新しい画像表現は3つのmapperネットワークに送られます。
mapperネットワークは、他の特徴を維持しながら画像の希望する属性を操作するように訓練されています。
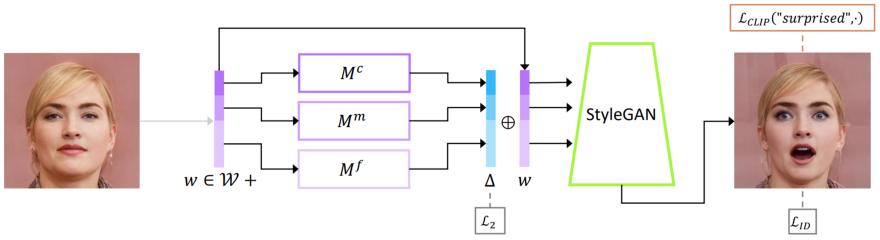
これらのネットワークはそれぞれ、ネットワーク内の異なる深さでエンコーダから情報を抽出する際に決定される。
粗いものから細かいものまで、特定の詳細レベルをマッピングする方法を学習する役割を担っています。
このようにして、大まかな特徴や細かい特徴を個別に操作することができるのです。
ここで、このマッピングを操作するためにCLIPモデルが使われます。
CLIPモデルは画像の内容を理解し、画像がエンコードされるのと同じようにテキストがエンコードされるので、学習の結果、マッピングはテキストの入力に応じて動くようになります。
このようにCLIPは、「中性的な顔」から「驚いた顔」というように、テキストから別のテキストへの変換を理解し、この同じ変換を画像のマッピングに適用する方法をマッピングネットワークに伝えることができるのです。
この変換はCLIPが制御するデルタベクトルで、テキストに起こったのと同じ相対的な変化と回転を潜在変数wに適用します。
修正された潜在変数がStyleGANの生成器に送られ、変換された画像が作成されます。
まとめると、CLIPモデルは、「a neutral face」から「a surprised face」のように、文の中で起こっている変化を理解し、エンコードされた画像表現に同じ変換を適用しています。
StyleClipの問題点はマッピングネットワークを訓練しなければならないことですが、論文の中でこの問題にも取り組んでいます。
その辺りについて興味があれば論文を読んでみてはいかがでしょう。
https://arxiv.org/pdf/2103.17249.pdf
実装に関しては後日紹介します。