StyleGAN2を使って自身の学習データで訓練させるとなるとデータ収集から学習時間を考えると相当大変です。
試すだけであれば、学習済みのデータがあるのでそちらを試して実際に生成するのは割と楽だったりします。
早速やっていきましょう。
車画像の生成
始めにランタイムをGPUに変更しておいてください。
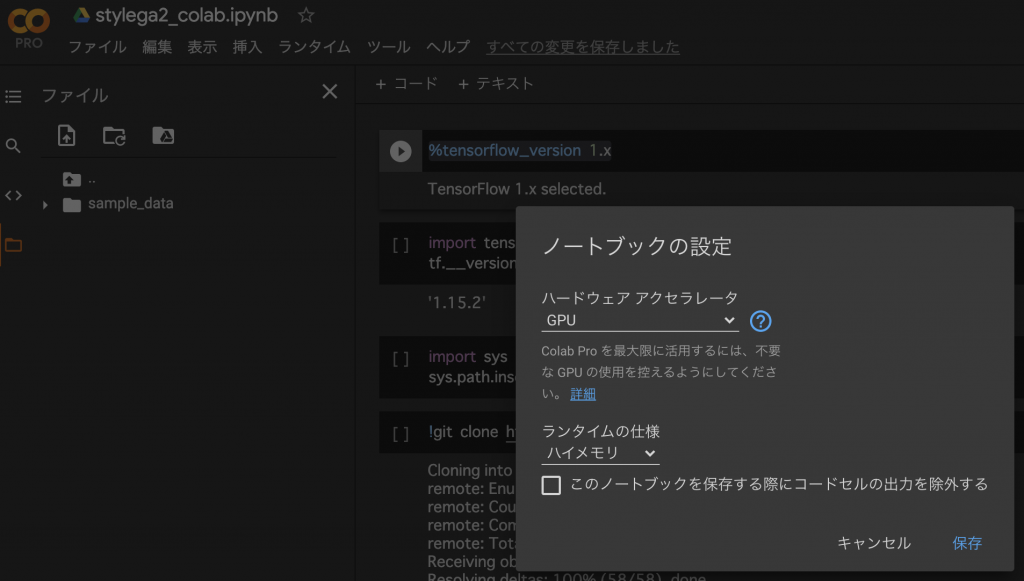
次に、tensorflowを使っていくのですが、デフォルトだと2系になってしまい、エラーが発生するので1系を選択するようにします。
ついでに1系が選択されているか確認のためにバージョンを表示しておきます。
%tensorflow_version 1.x
import tensorflow as tf
tf.__version__StyleGAN2をcloneしてくるわけですが、カレントディレクトリからでもStyleGAN2のモジュールを使えるように設定しておきます。
そして、cloneしておきます
import sys
sys.path.insert(0, "/content/stylegan2")
!git clone https://github.com/NVlabs/stylegan2.git早速、試してみます。今回は車の生成をしてみます。
ここではパラメーターについて詳しく説明しませんが、networkが学習済みモデルの指定、seedsが生成画像枚数と潜在変数の指定、truncation-psiが制約のパラメーターです。
!python /content/stylegan2/run_generator.py generate-images \
--network=gdrive:networks/stylegan2-car-config-b.pkl \
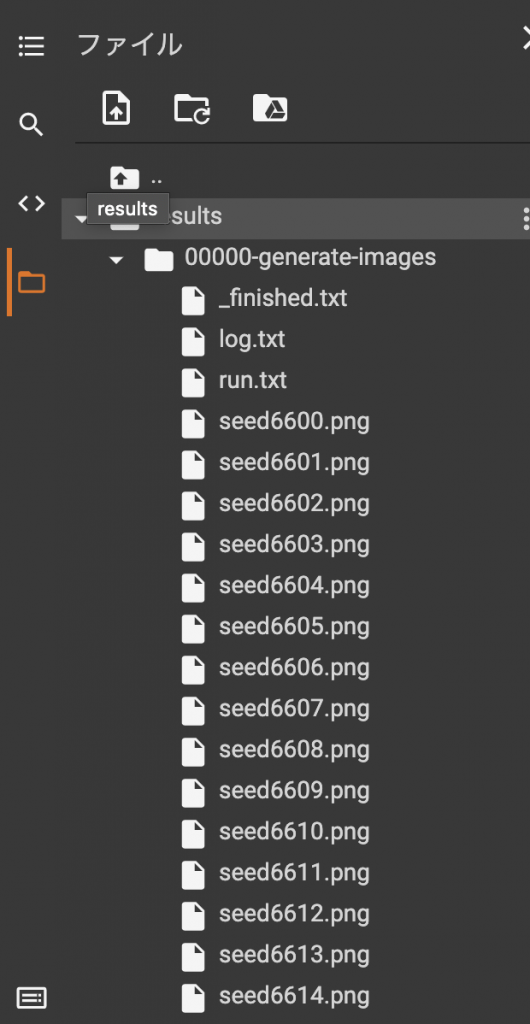
--seeds=6600-6625 --truncation-psi=0.5完了すると、resultフォルダが出来て中に生成画像が出来ているのが確認できたと思います。
これだけでStyleGAN2を試すことができました。
顔画像の生成
まずは、出力先のフォルダを作成しておきます。
!mkdir out続いて、潜在変数を作成するための関数を用意します。
def seeder(seeds, vector_size):
result = []
for seed in seeds:
rnd = np.random.RandomState(seed)
result.append( rnd.randn(1, vector_size) )
return result後出しになりますが、必要なパッケージをインストールしておきます。
import argparse
import numpy as np
import PIL.Image
import dnnlib
import dnnlib.tflib as tflib
import re
import sys
import pretrained_networks次が1番重要な箇所で、画像生成プロセスの関数です。
これは、StyleGAN2のコードをほぼそのまま持ってきたので気になる方は公式のgithubを参照した方が分かりやすいです。
def generate_images(Gs, seeds, truncation_psi):
noise_vars = [var for name, var in Gs.components.synthesis.vars.items() if name.startswith('noise')]
Gs_kwargs = dnnlib.EasyDict()
Gs_kwargs.output_transform = dict(func=tflib.convert_images_to_uint8, nchw_to_nhwc=True)
Gs_kwargs.randomize_noise = False
if truncation_psi is not None:
Gs_kwargs.truncation_psi = truncation_psi
for seed_idx, seed in enumerate(seeds):
print('Generating image for seed %d/%d ...' % (seed_idx, len(seeds)))
rnd = np.random.RandomState()
tflib.set_vars({var: rnd.randn(*var.shape.as_list()) for var in noise_vars}) # [height, width]
images = Gs.run(seed, None, **Gs_kwargs) # [minibatch, height, width, channel]
path = f"/content/out/image{seed_idx}.png"
PIL.Image.fromarray(images[0], 'RGB').save(path)顔画像の学習モデルを読み込みます。
network_pkl = 'gdrive:networks/stylegan2-ffhq-config-a.pkl'
print('Loading networks from "%s"...' % network_pkl)
_G, _D, Gs = pretrained_networks.load_networks(network_pkl)最後にパラメータを指定して実行します。
vector_size = Gs.input_shape[1: ][0 ]
seeds = seeder(range(8000, 8020), vector_size)
generate_images(Gs, seeds, truncation_psi=0.5)20枚の画像が生成されました。ただ、それぞれの画像は完全に別物なので途中の変化は見えないのと、動画にするには画像枚数が少ないので改善していきます。
seeds = seeder([6660, 7770], vector_size)
STEPS = 300
diff = seeds[1 ] - seeds[0 ]
step = diff / STEPS
current = seeds[0 ].copy()
seeds2 = []
for i in range(STEPS):
seeds2.append(current)
current = current + stepこの状態で300枚の画像を生成していきます。
generate_images(Gs, seeds2, truncation_psi=0.5)無事完了できたら、生成した画像を動画形式に変換したいと思います。
!ffmpeg -r 30 -i image%d.png -vcodec mpeg4 -y test.mp4以上で生成過程の動画をすることに成功しました。
colab上に出力しているのでこのままだと消えてしまうので、必要であればドライブ上かローカルにダウンロードしておくのをオススメします。
備考
学習済みモデルには猫の画像や馬の画像もあるので色々と試してみてください。
- stylegan2-ffhq-config-a.pkl
- stylegan2-ffhq-config-b.pkl
- stylegan2-ffhq-config-c.pkl
- stylegan2-ffhq-config-d.pkl
- stylegan2-ffhq-config-e.pkl
- stylegan2-ffhq-config-f.pkl
- stylegan2-car-config-a.pkl
- stylegan2-car-config-b.pkl
- stylegan2-car-config-c.pkl
- stylegan2-car-config-d.pkl
- stylegan2-car-config-e.pkl
- stylegan2-car-config-f.pkl
- stylegan2-horse-config-a.pkl
- stylegan2-horse-config-f.pkl
- stylegan2-cat-config-a.pkl
- stylegan2-cat-config-f.pkl