象限分析は4つのセクションにデータを分類します。大量のデータがある場合に知りたい情報を絞って分析をする場合は象限分析が適しています。
下記の記事でも象限分析を利用しています。
他にもよく見る例としては市場分析やWebマーケティングの時にも使います。
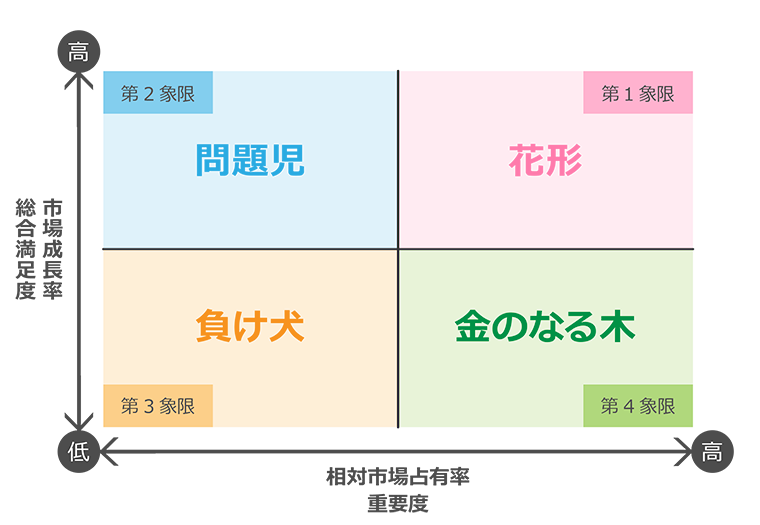
象限分析の特徴
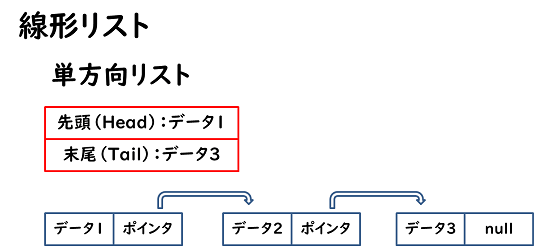
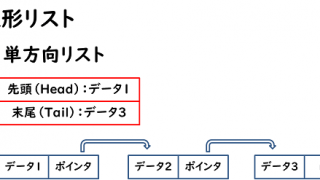
上記の画像を見ながら説明してみます。
その1:2軸構造
象限分析は必ず2軸で構成されます。この2軸の取り方が重要になってきます。
更に4象限に分けるには、x軸、y軸を全データの平均で分割にするなどが考えられます。
その2:軸が対比
軸が、大きい<=>小さいといった数値を比較する形であれば一つの指標であれば事足りますが(横軸の場合、右の方が大きいということが直感的に分かる)、具体的<=>抽象的のようなどちらがポジティブな内容かは一見するとわかりません。
そういった際には、二つ以上の指標を書いてあげる必要があります。
その3:4象限化
軸の対比を設定する際に、上下左右にどちらに何を持ってくるかで象限の配置が変わります。
基本的に右上に一番目指すべき事象が来るように設定します。
ですが、決まりはないのでどこに何が配置されても問題ありません。
Pythonで象限分析をしてみる
データセットはkaggleのHuman Development Report 2015を使用して行ってみます。
これは、国連開発計画によって公開された人間開発指数と呼ばれる「長く健康的な生活」、「知識へのアクセス」、「適切な生活水準」の達成度を示す要約指標です
一部のデータだけ使用して試してみます。
データ内容としては、
・HDI Rank:人間開発指数の順位
・Country :国名
・hdi:人間開発指数
・Life Expectancy at Birth:出生児の平均余命
・Gross National Income (GNI) per Capita:1人あたりの国民総所得
どのように事象分析して行くかというと、x軸に1人あたりの国民総所得(GNI)、y軸に出生時の平均余命を割り当てます。
この2つのメトリックに基づいて散布図を作成します。
今回の場合は収益性・成長・改善などを分析したいと考えます。
更に、4象限に分けるときの閾値はベンチマークとして定義できます。例えば、一つの国に対して前年比で分析したい場合、0を閾値として客観的なベンチマークとします。他国と比較したい場合、平均値もしくは中央値を用います。
今回は国同士の比較になりますが、他にも言語別だったり大陸別に比較したりもできます。
散布図のプロット
x軸に1人あたりの国民総所得(GNI)、y軸に出生時の平均余命をとった作成します。
csvデータを読み込んで中身を確認します。
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
df = pd.read_csv("/content/human_development.csv")
df.head()
今回は使わない教育年月(Mean Years of Education)なども入ってきているので必要なものだけ取り出してしまいます。
df = df.loc[:,['HDI Rank',
'Country',
'Human Development Index (HDI)',
'Life Expectancy at Birth',
'Gross National Income (GNI) per Capita']
]
df.head()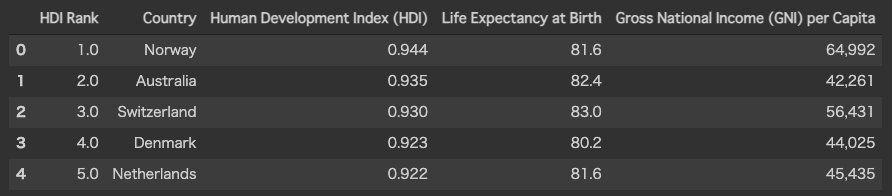
大分スッキリしました。
次にこのままだとカラム名が扱いづらいので、変更してしまいます。
df = df.rename(columns={'Human Development Index (HDI)': 'hdi',
'Life Expectancy at Birth': 'life_ex',
'Gross National Income (GNI) per Capita': 'gni'})
df.head()この状態で散布図をプロットしようとするとうまくいきません。
原因はデータ型にあります。カラム毎のデータ型を見てみます。
df.dtypesHDI Rank float64
Country object
hdi float64
life_ex float64
gni object
dtype: object
gniは数値として入ってきて欲しいのですが、object型になってしまっているので不都合になります。
そこでint型に変換してしまいます。
df['gni'] = df['gni'].str.replace(',','').astype(int)これで準備が整いました。
実際にプロットするコードを書いていきます。
plt.figure(figsize=(24,12))
sns.scatterplot(data=df, x='gni', y='life_ex')
plt.title(f"Countries : Gross National Income (GNI) per Capita vs Life Expectancy at Birth")
plt.xlabel("Gross National Income (GNI) per Capita")
plt.ylabel("Life Expectancy at Birth")
for i in range(df.shape[0]):
plt.text(df.gni[i], y=df.life_ex[i], s=df.Country[i], alpha=0.8)
plt.text(x=50000, y=58, s="Q4",alpha=0.7,fontsize=18, color='r')
plt.text(x=0, y=58, s="Q3",alpha=0.7,fontsize=18, color='r')
plt.text(x=-0, y=78, s="Q2", alpha=0.7,fontsize=18, color='r')
plt.text(x=50000, y=78, s="Q1", alpha=0.7,fontsize=18, color='r')
#Mean values
plt.axhline(y=df.life_ex.mean(), color='k', linestyle='--', linewidth=1)
plt.axvline(x=df.gni.mean(), color='k',linestyle='--', linewidth=1)
plt.show()
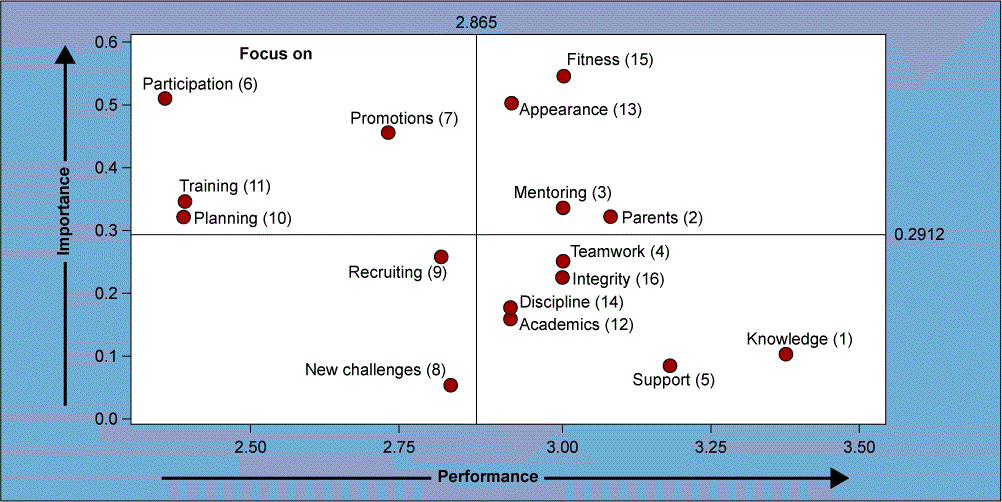
4象限に区切ってプロットすることができました。プロットしたデータを見るとlogのグラフに似ていますね。
このデータからわかることは、Q1は要約指標の元で他の国よりもパフォーマンスが優れています。各国の目標はQ1に到達することです。
Q2はGNIを改善することで、目標を達することができます。
Q3は二つのパラメーターで遅れをとっているので具体的な措置を講じる必要があります。
Q4は平均余命に影響を与える要因を特定し、対処する必要があります。
ただ、データを見ただけでは分からないことも図に起こすことで見えてくるものあります。
これも1種のデータ分析になりますので、kaggleなどのデータセットで色々と試してみると面白いです。