物体検出のこれまでの沿革を辿ると主に3つに大別できます。
slide window方式:Deformable Parts Models(DPM)
region proposal方式:R-CNN,Fast R-CNN
end-to-end方式:Faster R-CNN, YOLO, SSD
slide window方式
設定したウィンドウの大きさで、画像全体を1箇所ずつ検出していき、同時に識別もしていきます。
これは、無駄な工程が多数が含まれているので、処理速度と精度に難がありました。
region proposal方式
物体だと思われる場所を検出して、その検出した場所の情報をディープラーニングにかけていました。これも抽出した領域をディープラーニングにかけて識別処理を行っているため処理速度に難がありました。
end-to-end方式
region proposal方式で行っていた、ディープラーニングの識別処理と検出をディープラーニングのレイヤーに1つにまとめたものです。
deep neural networkが処理を一貫して行ってくれるので、高速・高精度な検出手法になります。
現在の物体検出モデルのSOTAはRetinaNetかFCOSだと思います。
YOLOv3(You Look Only Once)
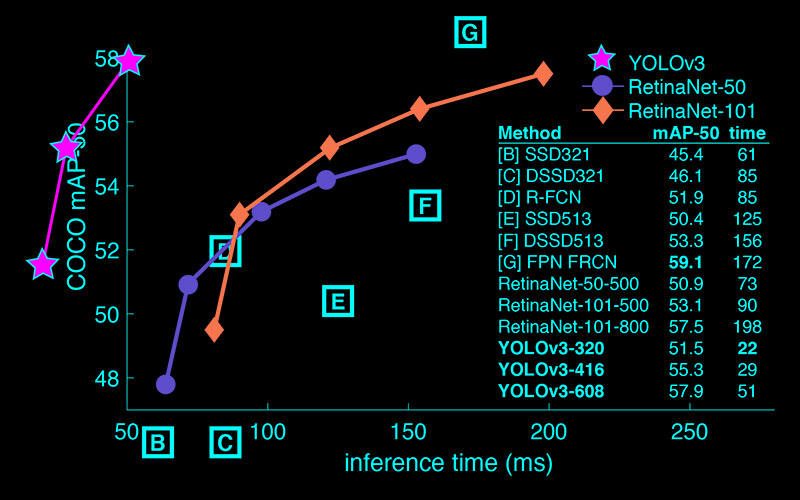
YOLOv3の特徴としては、推論時間が早く精度もそれなりに出ることがあげられます。
更に、DarkNetの一部となっており、DarkNet自体は自然言語処理にも使うことができ、OSSでgithubに公開されています。
https://github.com/pjreddie/darknet
ここから実行環境を作っていきます。上記のgithubページからローカルにクローンしてきます。その後に、cd darknetをターミナル上で行い、darknet配下に移動します。
そして、makeコマンドを実行してビルドして実行バイナリに変換します。
次にdarknetのHPからモデルのダウンロードを行っていきます。
ファイルが重たいので、結構時間がかかります。wget https://pjreddie.com/media/files/yolov3.weights
最後に実行していきます。
引数がdetectオプション、コンフィグファイルの読み込み、重みのファイル、検出したいファイルになっています。./darknet detect cfg/yolov3.cfg yolov3.weights Lena.png

本来ないものでも検出されていますが、これは学習時のデータに影響されています。
今回は既に学習済みのモデルを使用しているので、独自に学習させてモデルを使用してみて変化を見てみるのも良いと思います。
ウェブカメラの映像分析
YOLOの時にクローンしてきた、darknet配下にMakefileファイルがあるので、テキストエディタなどで開き、
GPU=0
CUDNN=0
OPENCV=0
OPENMP=0
DEBUG=0
となっている箇所の、OPENCV=0をOPENCV=1に修正して保存します。
そして、openCVがインストールされている状態で、makeコマンドを再度打ちます。
注意点としては、コマンドラインからopenCVを使う場合にはPATH設定を.bash_profileなどに書き込んで有効にする必要があります。
※pkg-configのPATHも通してあげる必要があります。
macの方であれば/usr/local/lib/pkgconfigに通してあげれば問題ないと思います
上記の設定ができたタイミングで、./darknet imtest data/eagle.jpgを実行してあげるとプログラムが動きます。

次に、ウェブカメラからリアルタイムに直接認識するプログラムを動かしていきます。
これもすごく簡単で、./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weightsとしてあげれば動きます。
ここで注意点として、yolov3.weightsを使用するとマシンスペックによっては負荷がかかりすぎて動かないことがあるので、その際は、軽量化されたyolov3-tiny.weightsを使用します。
下記のコマンドでダウンロードします。wget https://pjreddie.com/media/files/yolov3-tiny.weights
ダウンロード後に、./darknet detector demo cfg/coco.data cfg/yolov3-tiny.cfg yolov3-tiny.weightsを実行してください。
FPSが1程で表示できるので、試す分には問題ないくらいです。
更にFPSを早めるために、pytorch版のYOLOを使用します。
下記のURLからクローンしてきて、重みファイルとcfgファイルのyolov3-tinyは上記から持ってきて、yolov3-tiny.weightはクローンしてきたディレクトリと同じ階層に、yolov3-tiny.cfgはcfgディレクトリ内に格納します。
https://github.com/ayooshkathuria/pytorch-yolo-v3
そして、python cam_demo.pyを実行します。
もし、モジュールエラーが出れるようであれば、必要に応じてインストールしてください。
補足
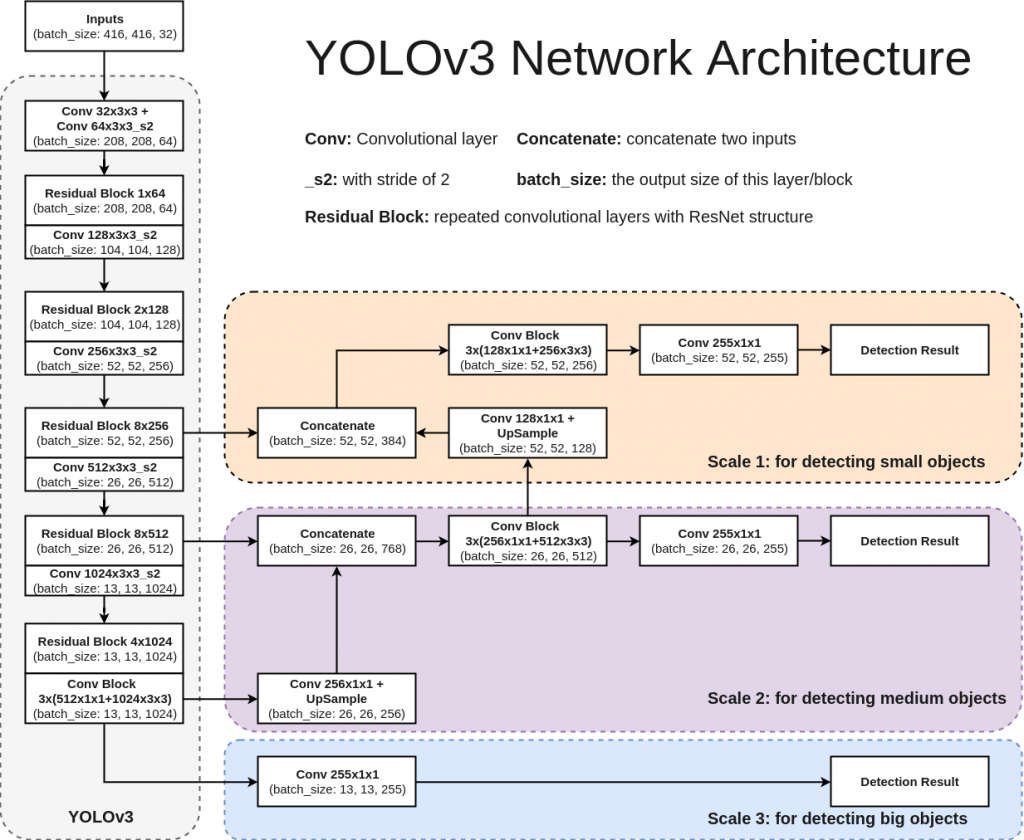
YOLOv3の仕組み
YOLOv3は他の手法と比較して、計算量が少なくすみます。
理由としては、今までの手法がBounding Boxを検出して領域毎にCNNで位置とラベルを推定しているので領域の個数分だけCNN計算が発生しているのに対して、
領域をメッシュ状に区切り、セル毎に学習します。学習内容はオブジェクトを含んでいるか、Bounding Box、推定確率です。そして、1つの入力画像がCNNに入り、メッシュ状に区切ったセル毎に(S_w * S_h * {B * (x, y, w, h, objectness) + クラス数})の情報が入っています。
S_w, s_h : 縦と横のメッシュで区切られたセル数
B:セル毎に幾つのBounding Boxを推定するか
YOLOで使用されているCNNはDarknet-53で53個の畳み込みレイヤーがあります。
特徴としては、Resnetを使用することで精度を高めています。
そして、1つのネットワークで複数の出力を行うことで高速化しています。