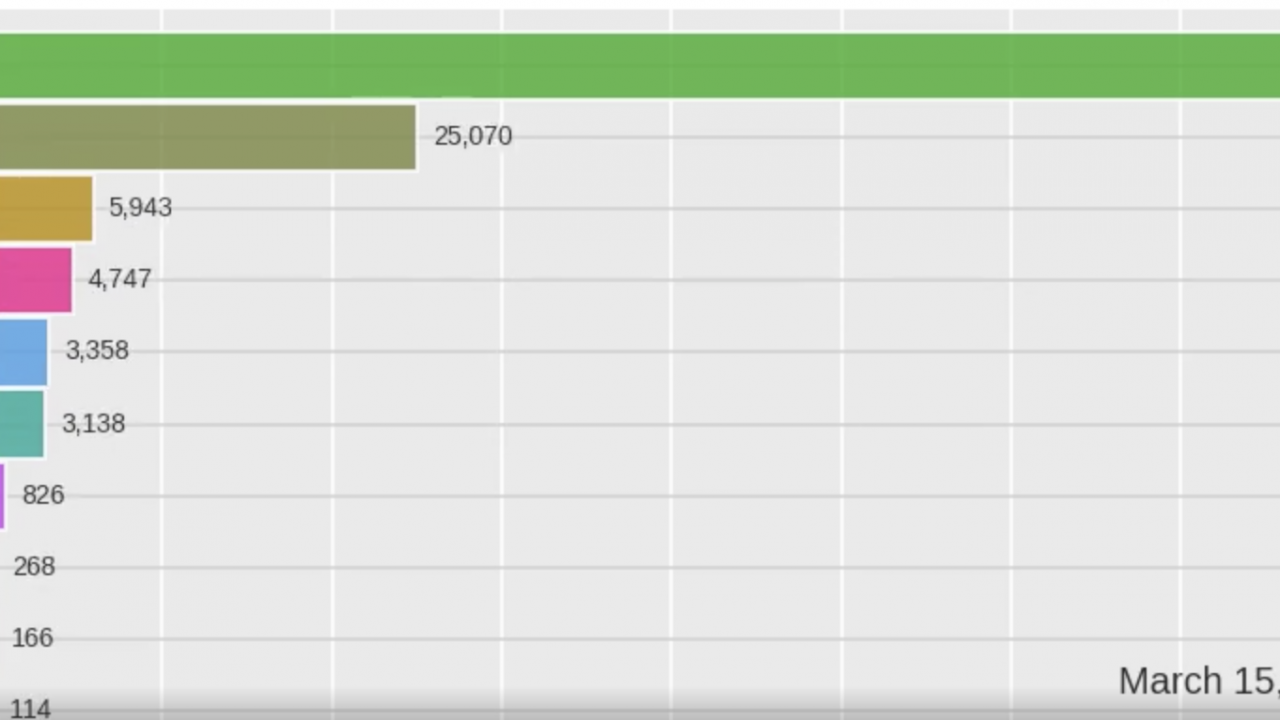
前回の記事で、bar chart raceでランキング表を時系列で推移する動画を作成しました。
ただ、使用したデータがほとんど前処理を必要とせずに表示できたので、pandasで前処理をして表示する過程についても学んでいきます。
使用するデータは、COVID-19症例のデータです。
検索すると、様々なデータが転がっているのでお好きなデータを使用してもいいですが、同じように試したい方はこちらのデータを使用してください。
COVID-19データ(参考):https://data.humdata.org/dataset/novel-coronavirus-2019-ncov-cases
ゴールとしては、主要国の感染者数の推移をランキング化します。
早速やっていきましょう。前回と同じくcolabを使用します。
セットアップ
まずは、前回と同じくbar chart raceをインストールして、必要なモジュールをインポートしておきます。
!pip install bar-chart-raceimport pandas as pd
import bar_chart_race as bcr
import matplotlib.pyplot as plt
plt.style.use("seaborn-whitegrid")
%matplotlib inlineデータ読み込み
colabにCOVID-19のデータを上げて読み込むようにします。パスは適宜変えてください。
df = pd.read_csv('/content/covid-data.csv')
df色々なカラムがありますが、もう少しデータについて詳しく見たいので「location、date、new_cases」だけ抽出して見ていきます。
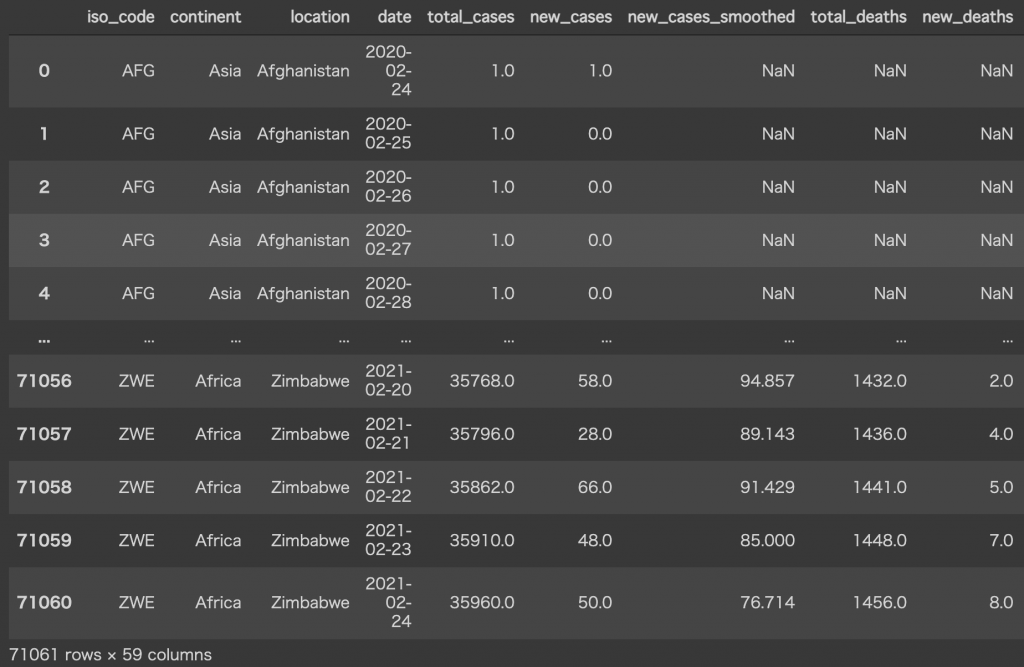
df2 = df[["location", "date", "new_cases"]]
df2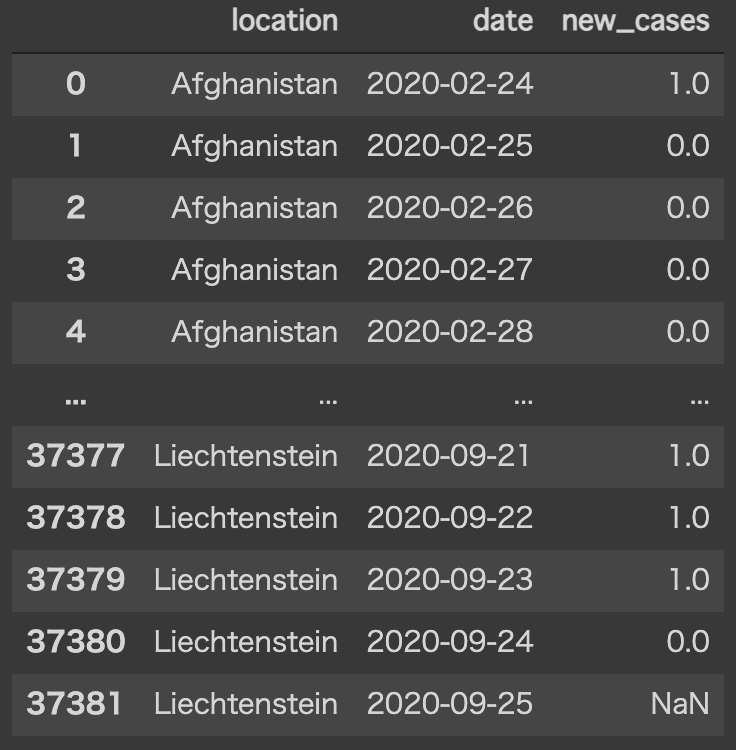
このデータを見ると、国毎に日付データを格納していることがわかります。
このままだと、bar chart raceで表示できないことは明らかなので、ピボット関数を使用して使いやすい形に変えます。
具体的には、日付と国別の症例数をクロス集計します。
df = df.pivot(index="date", columns="location", values="new_cases").reset_index().rename_axis(None, axis=1)
df421行あるので、1年と2ヶ月くらいのデータ量ですね。国の数は215カ国あるわけですが、冒頭でも記載したように主要国のみに絞っておきます。全部やると描画するのが大変なので・・・
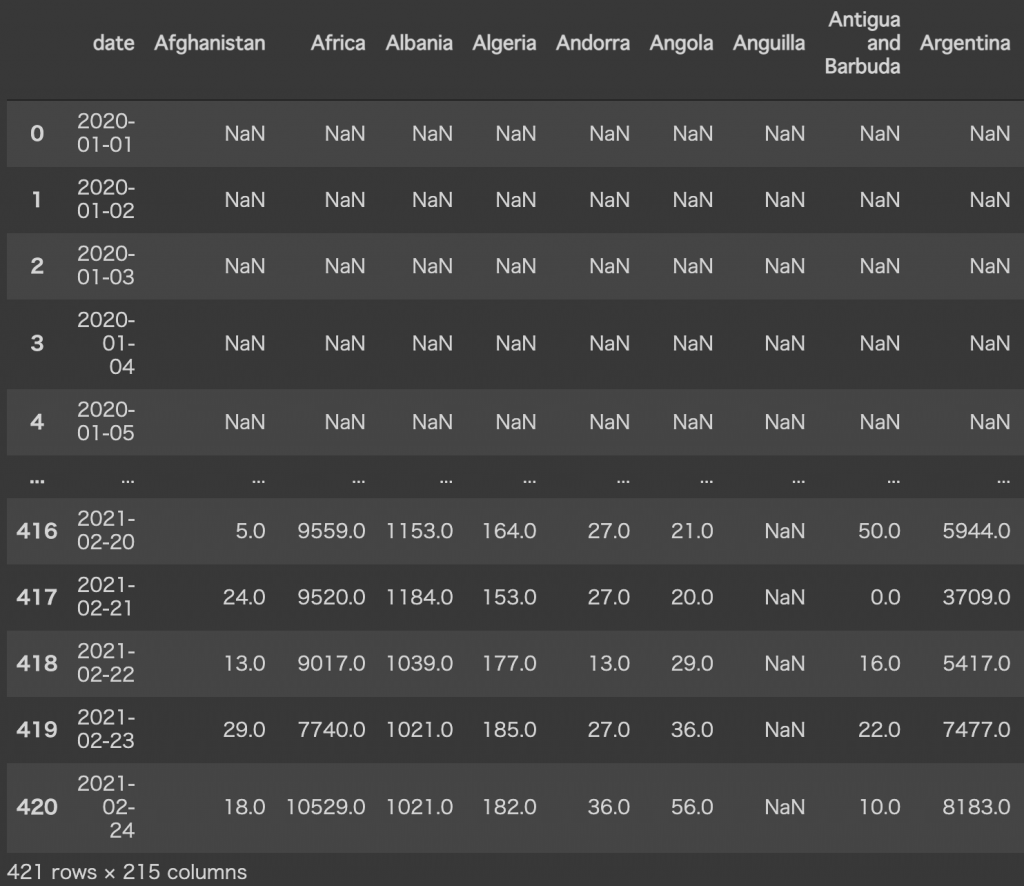
別の国の遷移を見たい方は好きな国を選択してください。仮で下記のように10カ国指定しました。
df = df[["date", "United States", "China", "Japan", "Germany", "India", "United Kingdom", "France", "Italy", "Brazil", "Canada"]]今のままだと、欠損値があるため上手く描画できません。では、どのように埋めていくのかというと、計測した日付が新しいほどNaNが多いですが、これは日付が新しいほど症例数がまだ確認できていないケースが多いわけです。
そこで、まず最初に症例を確認できた日付まで欠損値を削除します。
早速、一番最初に観測できた日付を確認します。
import math
for i in df.columns[1 :]:
j = 0
while math.isnan(df[i].iloc[j]):
j = j + 1
print(i, j)0~22番目までの行を削除できることがわかりました。

for i in range(22):
df.drop(index=i, inplace=True)
df.head()削除できたわけですが、indexがずれてしまいました。。最終的にindexには日付を割り当てたいので、このままだと不都合が生じでしまいます。
そこで、indexを改めて割り当てておきます。
df = df.reset_index()
df.drop(columns="index", inplace=True)この状態でもまだ欠損値があるため、除去していきます。
print(df.isnull().sum())
df = df.fillna(0)ここで少し改良としてfloat型の要素を全てint型に変換しておきます。というのもfloat型はint型よりメモリを大きく消費するため、描画するのに時間がかかります。
要素を見てみると、特にfloat型である必要もないのでint型に変換してしまいます。
for i in df.columns[1 :]:
df[i] = df[i].astype(int)最後にdateの処理をしていきます。実はdateの指定の仕方にはいくつかあり、今回は別の方法でやっていきます。
表示形式としては「(‘January’, ’23,’, ‘2020’)」の形を目指します。
まずはじめに、月と対応する英語表記を辞書型で定義します。
monthDict = {"01":"January", "02":"February", "03":"March", "04":"April", "05":"May", "06":"June", "07":"July", "08":"August",
"09":"September", "10":"October", "11":"November", "12":"December"}後は、dateの中身を適宜置き換えていけば作成することができます。
monthDict[df["date"].iloc[0].split("-")[1 ]], df["date"].iloc[0].split("-")[2 ]+",", df["date"].iloc[0].split("-")[0]これを関数化して、全てのdateに適応します。
def correctDate(dateStr):
strList = dateStr.split("-")
dateFormat = str(monthDict[strList[1 ]]) + " " + str(strList[2 ]) + ", " + str(strList[0])
return dateFormat
df["date"] = df["date"].apply(lambda x: correctDate(x))
dfdateが目指した形になっているのが確認できます。
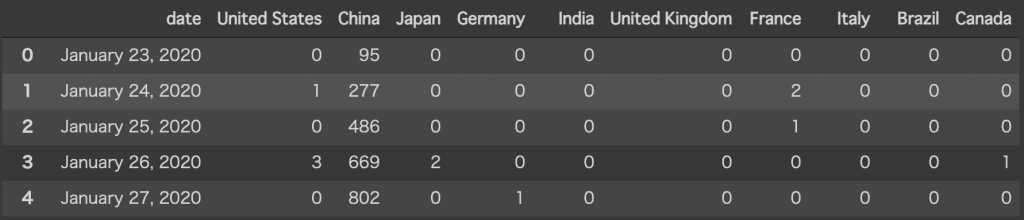
後は、indexをdateに置き換えてあげるだけです。
df.set_index("date", inplace=True)これで描画するための前処理が完了しました。
実は、これだけでは不十分な点があります。
それは、日付毎に表されているのは新規の症例数であって、累計ではないため推移を見るのには向いていません。
そこで、日付ごとに前日分を加算する必要があります。それも便利なメソッドがあるので1行で終わります。
sumData = df.cumsum(axis=0)累計表示になっているのが確認できます。このデータで描画して見ます。
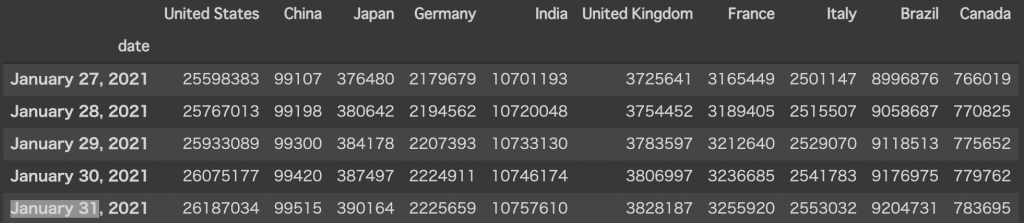
bcr.bar_chart_race(df=sumData, filename=None, period_label = {'x':.75, 'y': .1}, title='COVID-19 Cases by Country')以上で完了です。前回よりもデータ量が多いので時間はかかりますが放置しておけば勝手に終わります。
pandasを使用しての前処理とbar chart raceの流れを見てきました。
自身でデータを整えて表示する必要があるので、pandasの学習にはいいかもしれません。













