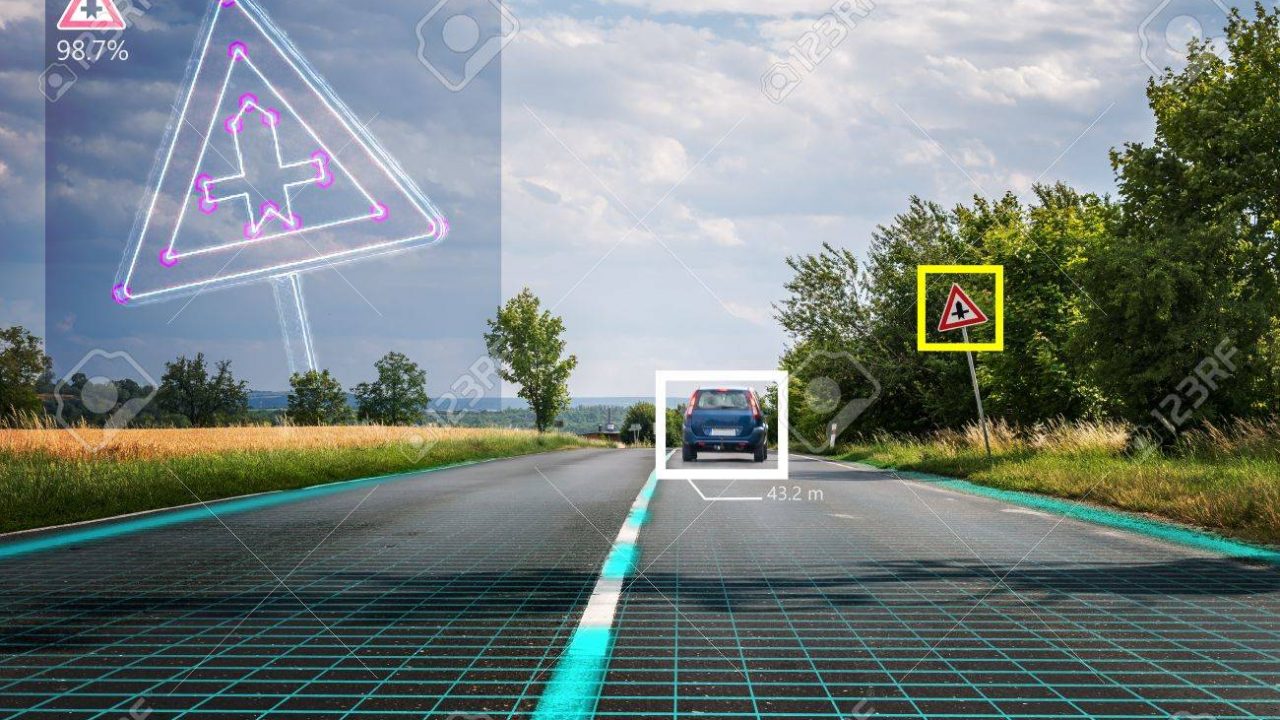
イントロダクション
コンピュータービジョンは、人間の視覚で行っていることをコンピューター側で行うことを追求する分野です。これを発展させていくと、画像や動画などを解析することを自動で行うことができます。
人工知能や機械学習が脚光を集めた結果、この学問も注目を浴びています。
画像認識やオブジェクトトラッキング、マルチラベル分類などで使用されます。
コンピュータービジョンシステムを構成する主要な箇所を紹介します。
コンピュータービジョンシステムのフローとして下記があります。
1、画像を読み込ませる
2、特徴抽出機を使用して、1)の画像に対し前処理して抽出する
3、機械学習システムは、2)で抽出された特徴を利用してモデルを訓練して予測を行う
これらのステップでデータがどのような処理を行われているのかを簡単に説明していきます。
画像を読み込ませる
コンピュータービジョンシステムを実装するには、2つの主な要素について考える必要があります。
1、画像取得のためのハードウェア(スマホカメラ、Lider、etc..)
2、画像処理のためのソフトウェア
更に、コンピュータービジョンシステムを導入するにはロバストのテストが欠かせません。
これは、実験と本番では環境の変化(システム照明の変化、向きの変化、スケーリング)が顕著に出てくるため、出来る限り環境の変化に不変かつ設計されたタスクを繰り返し実行できるシステムである必要があります。
これらの条件を満たすためには、ハードウェア・ソフトウェアに何かしらの形で制約を適用する必要がある可能性が高くなります。
ハードウェアデバイスから取得した画像をソフトウェア側で処理するのも一苦労です。
その1つの要因として、色を数値で表現する方法は数多くあります。
有名どころとしては、RGB・HSVの2つです。
HSVは聞き慣れないかと思いますので、一つメリットを挙げておくとHS (色相、彩度) 成分を使用することで、システム照明を不変にすることができます。
特徴抽出機
画像の前処理
画像がシステムに入ってきて色空間を使って数値に変換されると、様々な処理を施すことが可能になります。
点演算子:画像内の点(ピクセル)を使用して、元画像を変換することができます。
ここで重要なのが画像の内容は変更していない点です。変換の例としては下記があります。
・強度正規化
・ヒストグラム均等化
・閾値の設定
今回の処理は人間の視覚で画像をより認識しやすくするために使用されますが、コンピュータービジョンシステムとしては必ず効果がある訳ではありません。
グループ演算子:点のグループを取り出して、そこから1つの点を変換させたものを作成します。
これは、一般的に畳み込みの箇所で使用されます。
そして、変換結果を得るために様々なタイプのカーネルを画像に畳み込みます。
カーネルの例としては、直接平均化・ガウス平均化・メディアンフィルタがあります。
画像に畳み込み演算を適用すると、結果的に画像のノイズ量を減らし、平滑化を向上させます(画像がぼやけることもあります)。1つの点を作成するのに、複数の点を使用しているので、新しい画像は元の画像よりも小さくなります。この問題の対策として、ゼロパディングが良く用いられます。ゼロパディングを用いることで、元画像と同じサイズの変換画像が得られます。
畳み込みには重要な制限として、大きな画像サイズを扱えない点があります。この問題に対しては、フーリエ変換を用いることが考えられます。
参考:https://stats.stackexchange.com/questions/296679/what-does-kernel-size-mean/296701
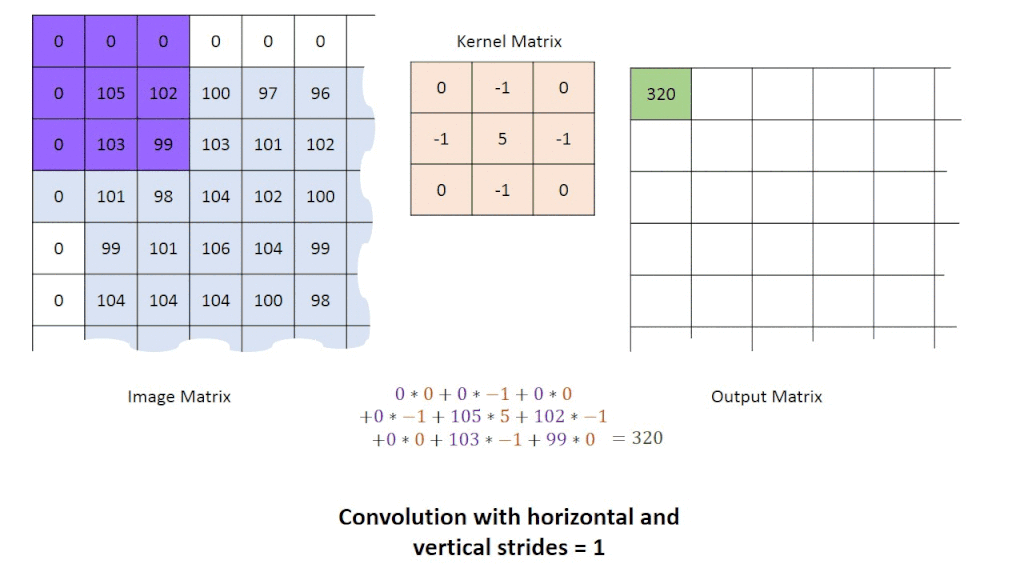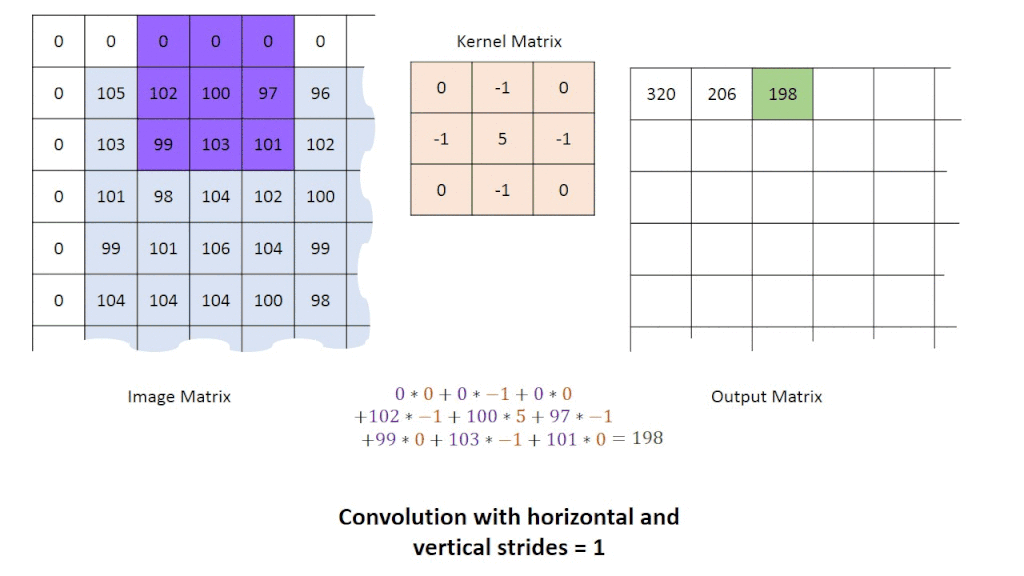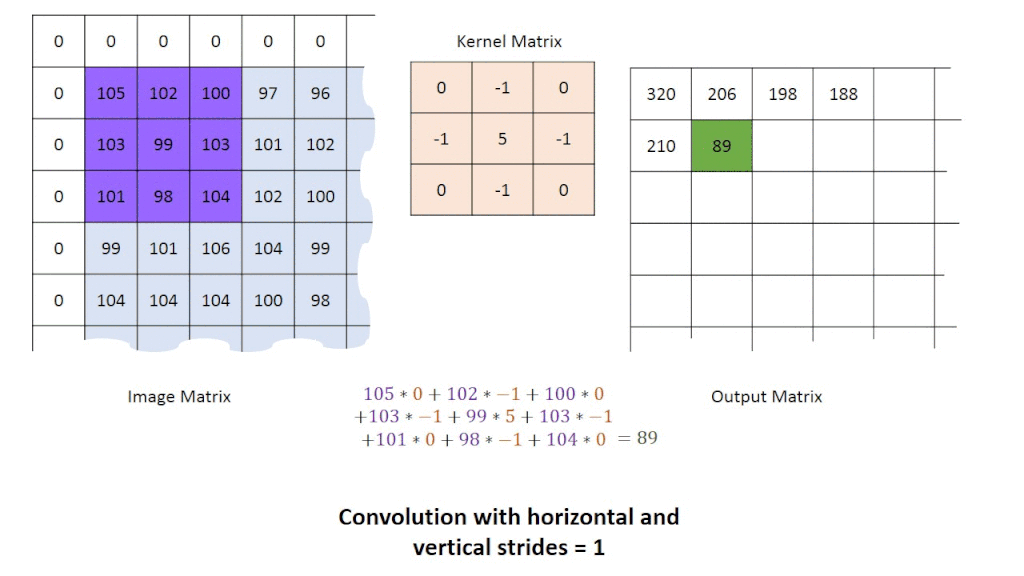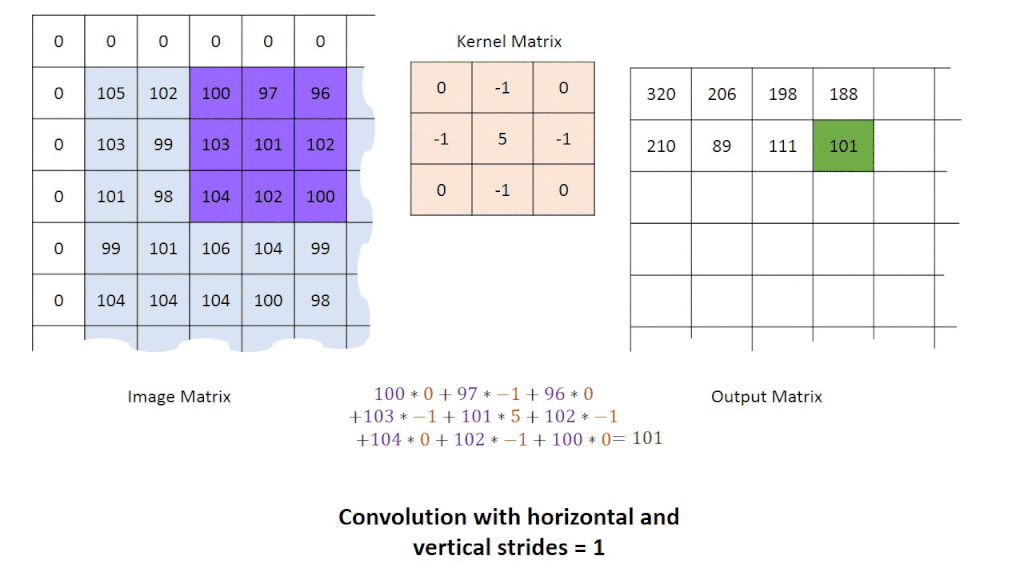
画像を前処理した後は、エッジ検出(例:プレウィット演算子、ソーベル演算子、キャニーエッジ検出)やハフ変換などの手法を用いて、画像内のエッジや形状を抽出するために、高度な技術を使用していきます。
特徴抽出
画像を前処理すると、特徴抽出機を使用して画像から抽出できる特徴形態は4つあります。
1、グローバル特徴量:画像全体が1つとして分析され、特徴抽出機からは1つの特徴ベクトルが出てきます。例としては、ビニングされたピクセル値のヒストグラムです。
2、グリッドもしくはブロックベース特徴量:画像を異なるブロックに分割し、それぞれのブロックから特徴を抽出します。画像のブロックから特徴を抽出するために使用される代表的な手法の1つが、Dense SIFT(Scale Invariant Feature Transform)です。この特徴量は機械学習モデルの訓練に良く用いられます。
3、領域ベース特徴量:画像を異なる領域に分割し(閾値化やk-meas custeringなどの手法を用いて、連結成分を用いてそれらをセグメントに連結する)、それぞれの領域から特徴量を抽出する。モーメントやチェインコードなどの領域や教会の記述技術を用いて特徴を抽出することができる。
4、局所特徴:画像内で単一の関心点が検出され、関心点の周辺に位置する画素を分析することで特徴が抽出されます。画像から抽出できる関心点の主なタイプはコーナーとブロブの2つで、これらはハリス&スティーブンス検出器やガウシアンのラプラシアンなどの方法で抽出することができます。最後に、SIFT (Scale Invariant Feature Transform)のような技術を使用して、検出された関心点から特徴を抽出することができます。局所特徴量は、通常、パノラマ/3D再構成を構築するために画像を照合したり、データベースから画像を取得したりするために使用されます。
参考:https://jp.mathworks.com/help/vision/ug/local-feature-detection-and-extraction.html
一連の特徴的な特徴を抽出したら、それらを使用して機械学習モデルをトレーニングし、推論を行うことができます。機能は、OpenCVなどのライブラリを使用してPythonで簡単に適用できます。
機械学習
コンピュータービジョンで画像を分類するために用いられる主な概念の一つに、BoVW(Bag of Visual Words)があります。BoVWを構築するためには、まず、画像の集合から全ての特徴を抽出して語彙を作成する必要があります(グリッドベースの特徴や局所的な特徴などを使用)。
次に、抽出された特徴が画像に何回現れたかを数え、その結果から度数ヒストグラムを作成します。
作成した度数ヒストグラムをテンプレートとして使用し、最終的にヒストグラムを比較することで、画像が同じクラスに属するかどうかを分類することができます。
この手順は、下記のフローになります。
1、SIFTなどのアルゴリズムを用いて、画像のデータセットから異なる特徴を抽出し、語彙を構築
2、K-meansやDBSCANのようなアルゴリズムを用いて、語彙内のすべての特徴をクラスタリングし、データの分布をようやくするためにクラスタの重心を使用します
3、最後に、語彙の異なる特徴が画像内に現れた回数をカウントすることで、各画像から度数ヒストグラムを構築できます
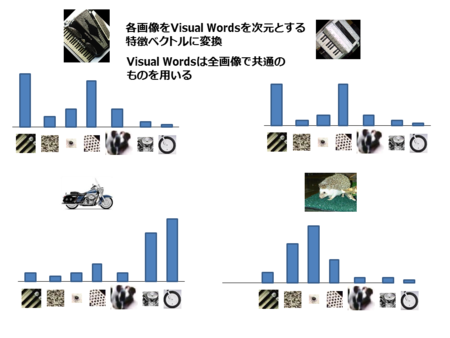
今では、CNNやRCNNのようなアーキテクチャが生まれたおかげでコンピュータービジョンのための代替ワークフローを構想することが可能になりました。
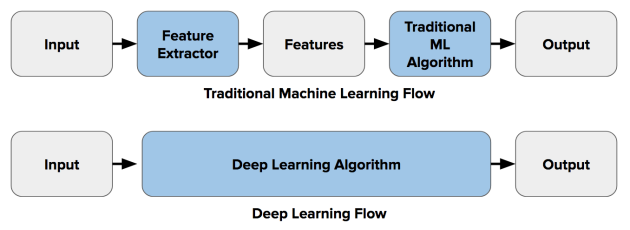
深層学習アルゴリズムは、コンピュータービジョンの特徴抽出と分類の両方のステップを組み込んでいます。














